
Published on
May 22, 2023
Try to look away, but there’s no denying it: AI is all around and bound to become more embedded in our lives moving forward. With the incredible progress and mounting buzz, questions arose from our CXO advisory board, which consists of over 70 Fortune 1000 CXO, CTO, CISO, and CIOs. “How can I set aside the hype and focus on what can be implemented today?”
Our team at Sierra put together a Generative AI in the Enterprise event, which brought together CXOs, founders building generative AI products and solutions, and leading experts on these technologies and recent advancements.
Vivek Farias, a tenured professor at MIT and two-time founder (his latest company is Cimulate), gave a fascinating thirty-minute talk summarizing five sessions of his Hands-On Deep Learning class and answering many of the questions the audience had around where we can focus on building today.
There's a mystique around how generative AI systems function. However, Farias explained how their underlying mechanisms are fairly straightforward. To make generative AI seem less like a black box, there are two essential concepts to understand:
- How these systems are trained to pay attention to words in context
- How developers instruction-tune these systems for various use cases.
Farias illuminated how data scientists have built on these concepts and developed generative AI into something everyone can use.
Context and Attention: How Computers Make Sense of Sentences
The simplest way to understand how language models work is to imagine a Google search. Imagine these words in the search bar: 2019 Brazil traveler to USA need a visa.
For humans, it’s easy to know someone from Brazil is traveling to the US. But this was a challenge for pre-2018 Google before they rolled out BERT, a natural language processing system.
What could humans do that computers hadn’t yet been trained to do?
It’s in the context. In language, meaning often relies on context. We understand sentences by not only thinking about individual words, but words strung together. And before BERT, computers discerned the meaning of words individually, which posed problems.
Consider this sentence: The train slowly left the station.
Without its surrounding context, station could refer to a train station or radio station. BERT was developed to weigh each word’s importance to the overall context by using an attention mechanism . In the sentence above, train is weighted as a contextually valuable word, which helps the system infer the correct meaning of station; colloquially, station ‘pays attention’ to train
This attention mechanism helps Google know our searcher is Brazilian, not American. The overall model is called a transformer.
These transformers make up the underlying technology for modern natural language processing.
Take a look at the two sentences above. First, “The animal didn’t cross the street because it was too tired.” The word it refers to an animal here. Compare that to it in the sentence: “The animal didn’t cross the street because it was too wide.” The attention mechanism employed by BERT is understands which word to pay attention to and predict the correct meaning of it in both cases. This is called self-attention.
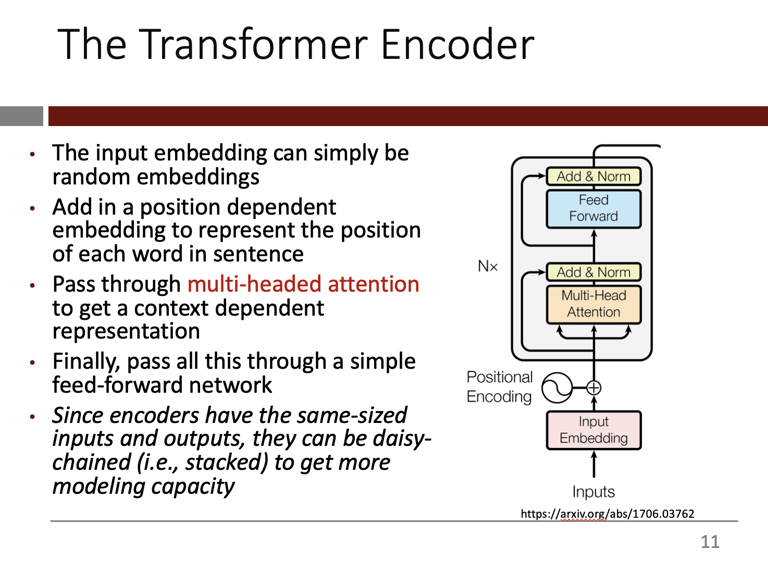
In his lecture, Farias went on to explain the architecture of the transformer encoder:
“You start with your inputs: ‘The train left the station slowly.’ You have some embedding that you get from somewhere…Positional encoding is something I didn’t talk about, but it is something that shows the position of words… Then you go to this thing called multi-headed attention, that’s just a fancy version of what I showed you earlier. [It] reweights these contexts. You have a simple feed forward network on top of this. Then you can just keep stacking these, one on top of the other.”
Today’s state-of-the-art generative AI models have introduced some tweaks, but they all retain this transformer encoder as part of the core functionality.
The GPT Family: Predicting Each Next Word
GPT (for Generative Pre-trained Transformer) is a transformer designed and trained by Open AI.. Unlike BERT, where a given the word can pay attention to any word in its context, GPT allows a given word to only pay attention to those that came before it. This allows GPT to function in a ‘generative’ fashion, predicting the next words given the words that have come so far.
GPT-3, a model within the GPT family, was trained using a transformer stack with 96 transformer blocks, with embeddings with dimensions of 12,228, and on ~100 billion sentences. Below, you can see the sequence of 3 different GPTs, each of which improved on the next with larger corpora and more stacks of transformers.

To illustrate how a GPT model functions, let’s say we typed in: the cat sat on the
Based on this input, GPT might predict the next word is mat, not fridge. It would output mat as the next word.
In his talk, Professor Farias explained more technical details behind the workings of GPT.
“You take the sentence, you start with positional embeddings, thinking about where in the sentence is each word. You pass this through the transformer stack…you now will get contextual embeddings to the sentence…After that, [you] run it through a feed-forward network.”
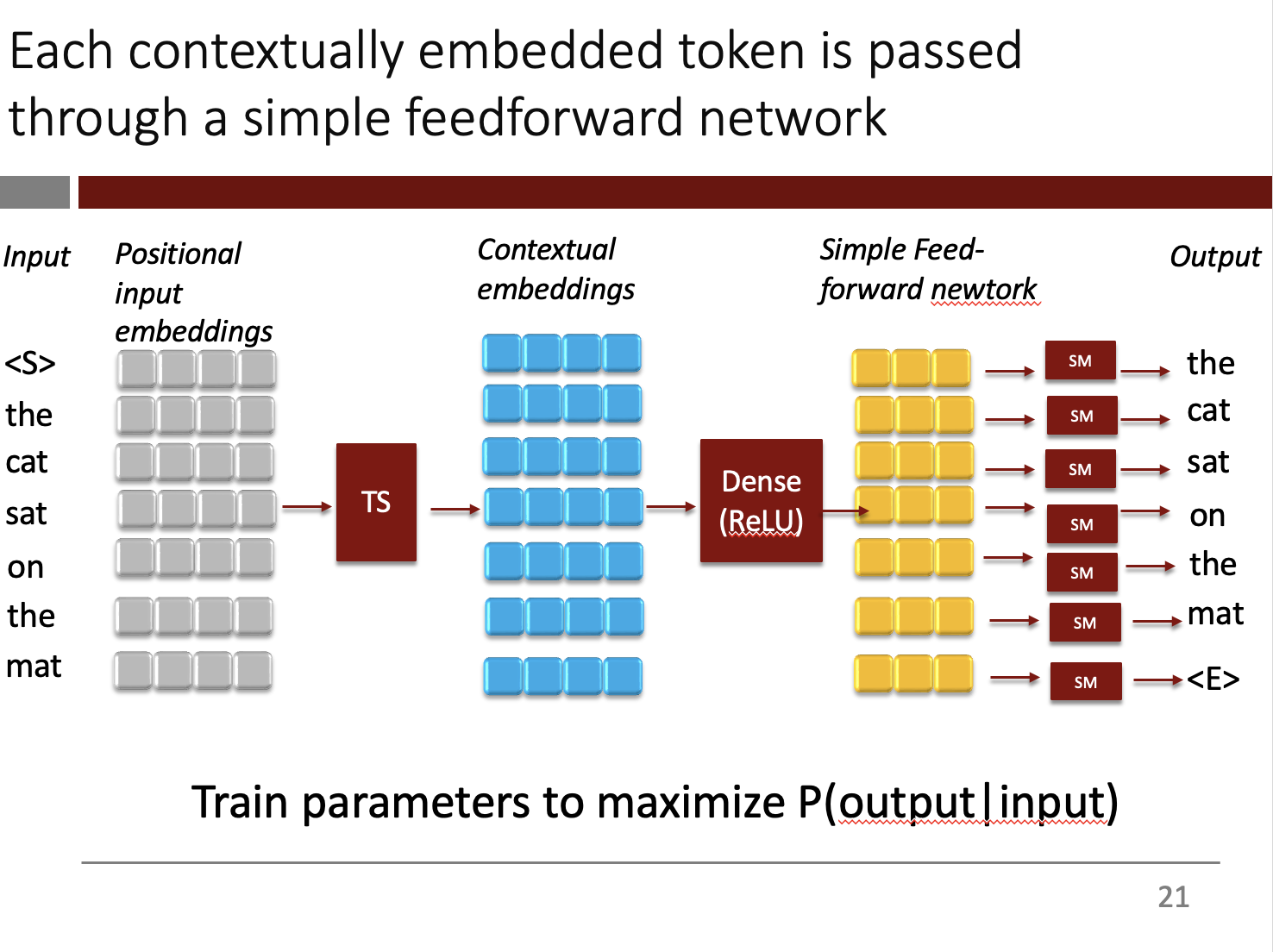
“All you are doing to train it, is feed it a bunch of sentences… Notice that this is completely unsupervised–I just need a sentence…You take these sentences, and all you are doing is training [GPT] to maximize the accuracy of the prediction.”
Yet GPT3 didn’t go viral when it came out in 2020. Part of the reason was that when asked a question, sometimes the answers were unhelpful or bizarre. After all, GPT models were developed to predict next words, not answer questions.
However, scientists saw great promise in GPT3. They discovered something that would shift natural language processing forever: given just a few examples of a given natural language task, GPT-3 exhibited the ability to learn the task, a phenomenon referred to as ‘few shot learning’.
Instruction Tuning Language Models
Building on the promise of few-shot learning, OpenAI built a corpus of human generated ‘instructions’ with the intent of using these instructions to make GPT-3 more adept at the conversational tasks ChatGPT is known for. These instructions ran the gamut from tasks such as asking for an email draft to generating code. With an initial corpus of around 10,000 such intstructions and a further, cleverly bootstrapped set of several tens of thousands more instructions, GPT-3 was ‘fine-tuned’ into what eventually powered ChatGPT.
: A generative AI model released in 2022 that currently has 1.16 billion users.
Harnessing Generative AI’s Power
Since ChatGPT’s release, we’ve seen a host of open-source, highly-functional natural language processing systems, all with the same basic architecture. LLama, Chinchilla. PaLM.
This generative AI explosion allows anyone to instruct tune these models quickly and cheaply. To do this, developers add to a system’s corpus and feed it instructions aligned with specific use cases. By doing this, we can teach these systems to work for us: write better product reviews, write screenplays, create FAQs, and so on.
During the lecture, Professor Farias described how on a Friday afternoon, he trained a generative AI system to output reviews given just a product description by feeding it 2,000 Amazon reviews. In under 3 hours and spending less than 4 dollars, he came up with impressive results. He quickly and cheaply was able to train a generative AI system to perform better for a specific use case..
You’ve now learned about the essential mechanisms of these systems: transformers, self-attention, large language corpuses, and instruction tuning. After seeing under the hood, how will you harness the power of generative AI to your specific use case?
Click the video below to watch Vivek Farias's talk at Sierra Ventures' Generative AI in the Enterprise event.

